
TAG CLOUD
- 3d
- API12F
- DCA
- DPR
- DUC
- DrillingInfo
- EIA
- ESP
- Enverus
- Gaussian
- H2S
- Huber regression
- L1 norm
- L2 norm
- L2 norm squared
- OLS
- P&ID
- PID loop
- ProMax
- RANSAC regression
- RVP
- SRP
- TheilSen regression
- VRU
- basins
- blowcase
- cashflow
- casing drawdown
- central tendency
- co-occurrence matrix
- completion
- confidence interval
- data-mining
- decline-curve-analysis
- dew-point
- downsizing
- drilling
- economics
- electric motor
- electric valve
- emissions
- energy-shortage
- flash
- gas
- gas engine
- gas-sample
- gear ratio
- heater
- heaters
- horizontals
- hypotheses testing
- learning rate
- level control valve
- level switch
- linear regression
- lube oil
- machine learning
- measurements
- negative sampling
- neural network
- nlp
- non-Gaussian
- non-normal
- non-parametric
- normal
- normality test
- oil
- oil-and-gas
- outliers
- pneumatic valve
- pressure control
- process engineering
- production
- recent-trend
- recycle
- robust linear regression
- screw compressor
- separator
- separator drawdown
- separators
- shutdown
- simulations
- skip-gram
- solenoid valve
- spatial median
- statistics
- stochastic gradient descent
- storage-tank
- suction control valve
- tank
- temperature control
- thermostat valve
- transmitters
- vapor recovery
- vector space model
- verticals
- visualization
- window size
- word vectors
- word2vec

Operation of Oil-Flooded Screw Compressor Explained
A detailed guide to oil-flooded screw compressor operations, covering compressor characteristics, operating capacity, unit P&ID, blowcase systems, control device mechanisms (valves and switches), pressure and temperature control, recycle mode, surface facility P&ID applications, lube oil contamination issues, electric vs. gas engine model comparisons, and more.

Predicting VRU Economics/Downsizing Timing For Declining Wells
Flash gas rates from low-pressure vessels (heaters, VRTs, and tanks) can decline much faster than anticipated, mirroring the rate of oil decline. In some cases, they can drop by half within just 3 to 6 months from IP. This post presents monthly process simulation results that model the decline of flash gas from low-pressure vessels as the well declines. An Excel sheet is also provided to help calculate VRU economics.
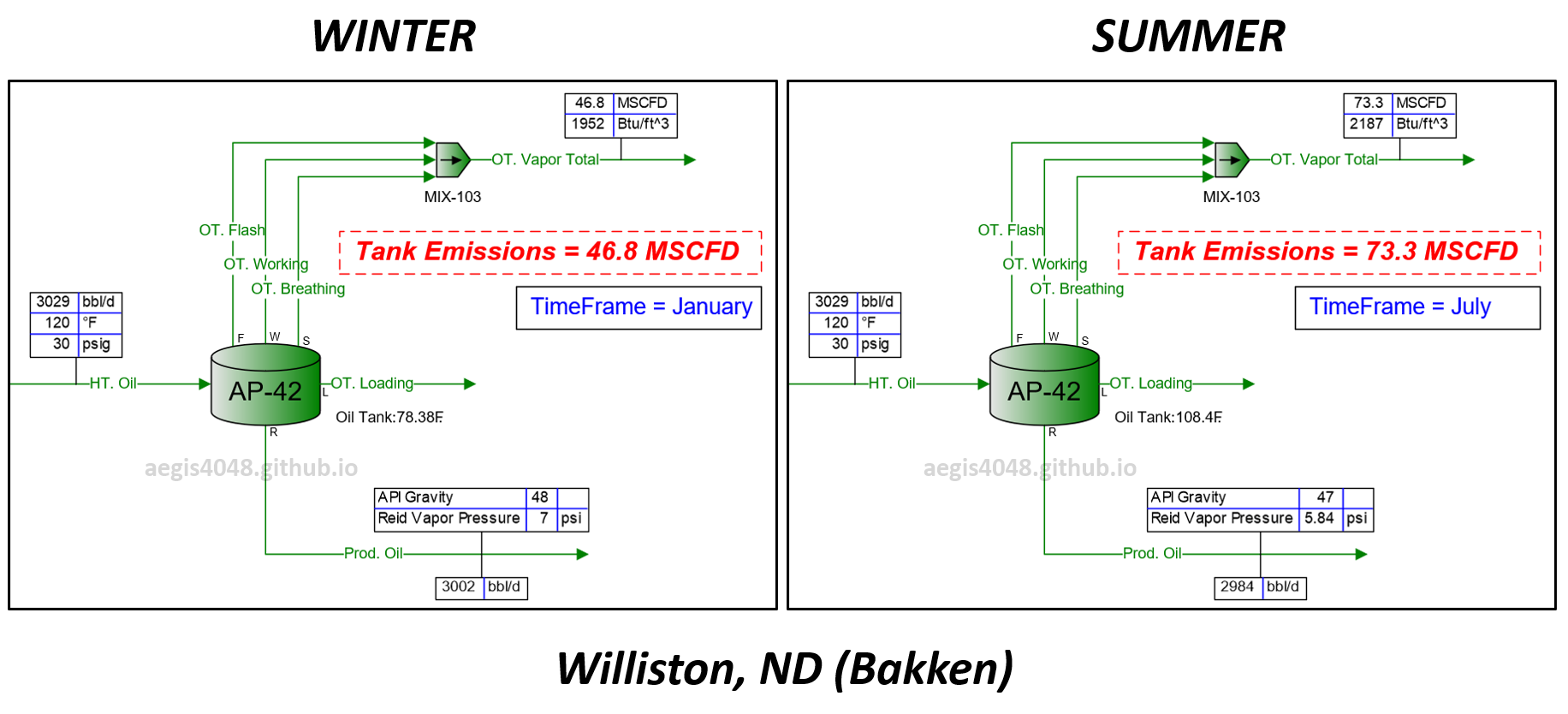
Impact of Seasonal Changes on Storage Tank Emissions
Storage tank temperatures rise in summer due to hot air, leading to higher emission volumes compared to winter. This temperature increase also impacts the dew point T, SG, and energy content (Btu/scf) of tank vapor. This post explains the phase behavior changes due to temperature shifts and provides a summary table with recommended operating capacity margins for emission handling systems across various regions.
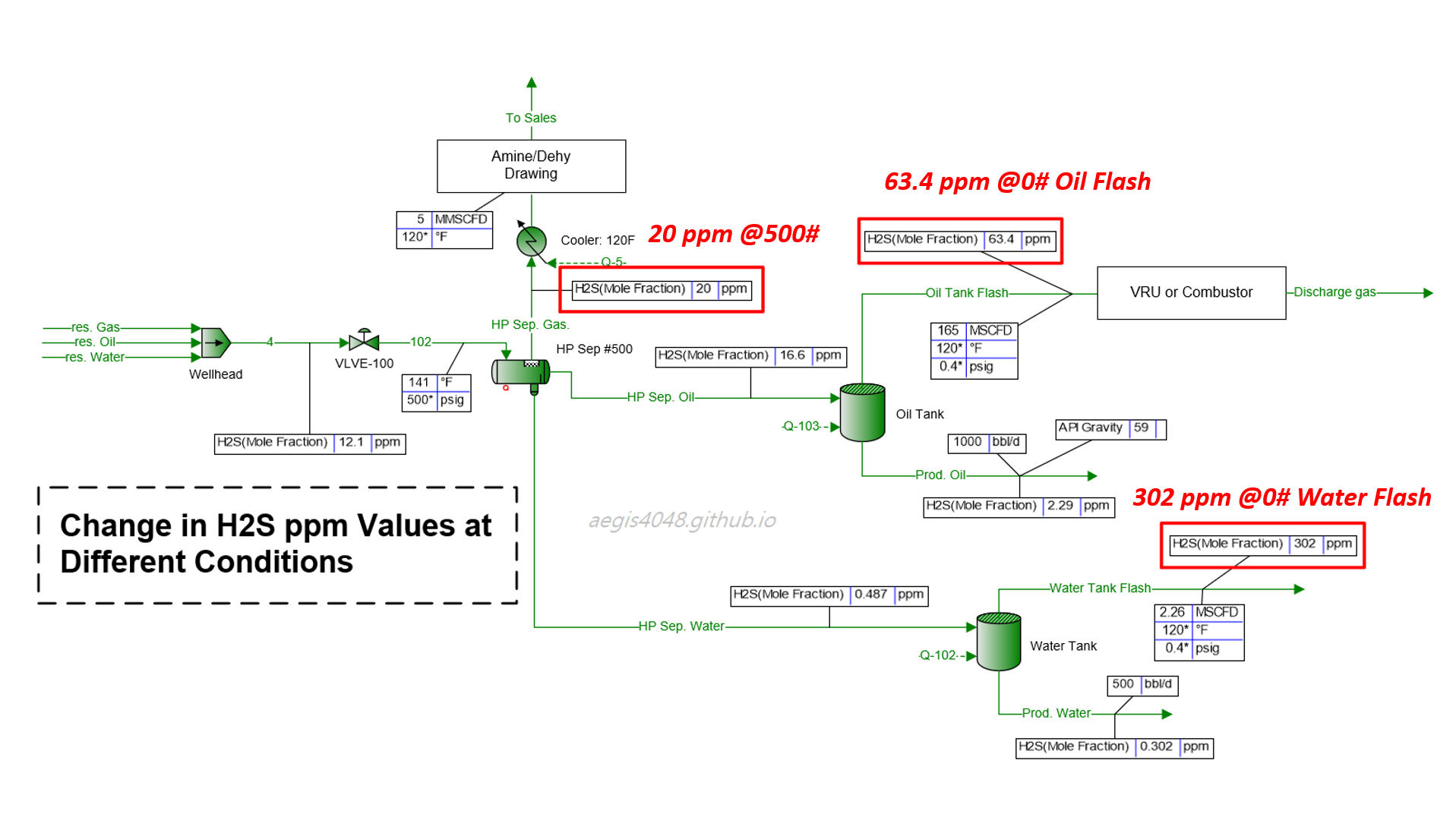
H₂S Levels: Why High-Pressure Samples Don't Tell the Full Story
H₂S ppm levels obtained from high pressure applications (HP separators) are often re-used for low pressure applications (atmospheric tanks). H₂S levels soar 3~25 times at low pressures. This post explains the thermodynamics behind H2S ppm level variations and provide simulation results summary for practical applications.
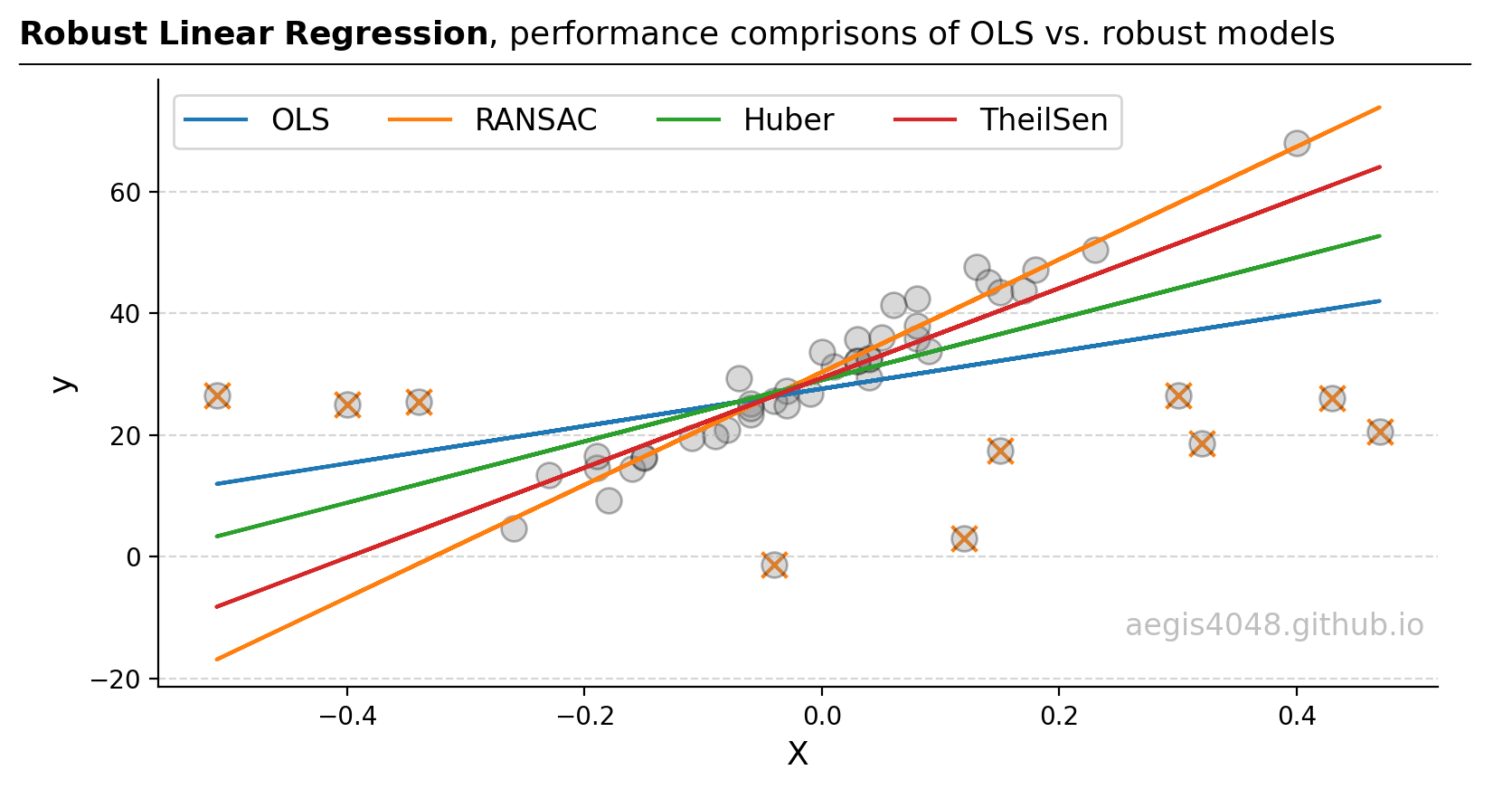
Robust Linear Regressions In Python
In regression, managing outliers is key for accurate predictions. Techniques like OLS can be skewed by outliers. This analysis compares OLS, RANSAC, Huber, and Theil-Sen methods, showing how each deals with outliers differently, using theory and Python examples, to guide the best model choice for different outlier scenarios.
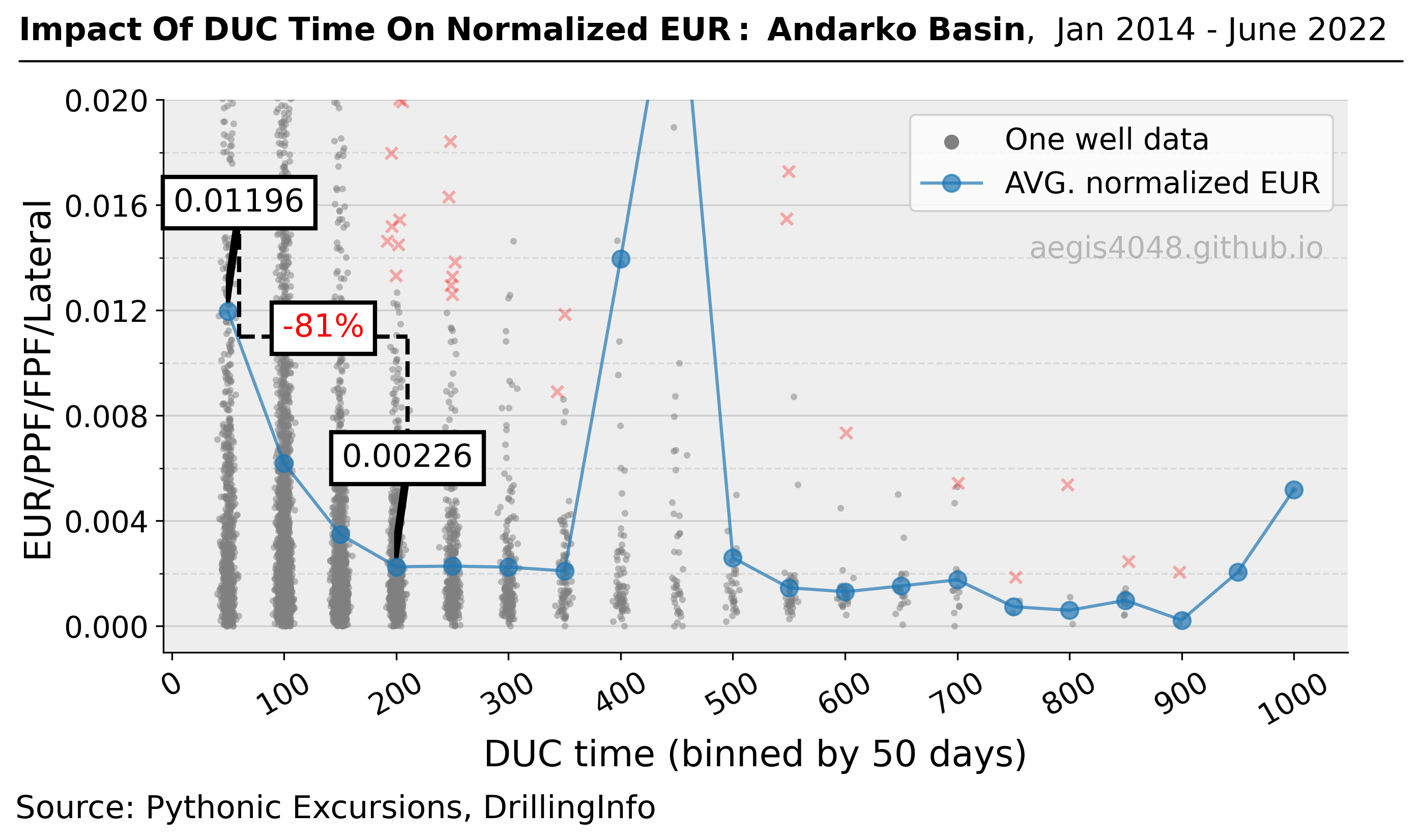
Quantifying The Impact Of Completion Delay Since Drilled On Production
In times of unfavorable commodity prices, operators may delay completion after drilling in the hope of a price recovery. The study conducted in this article shows why this may not be a financially sound idea for certain basins by quantifying the impact of DUC time on normalized EURs.
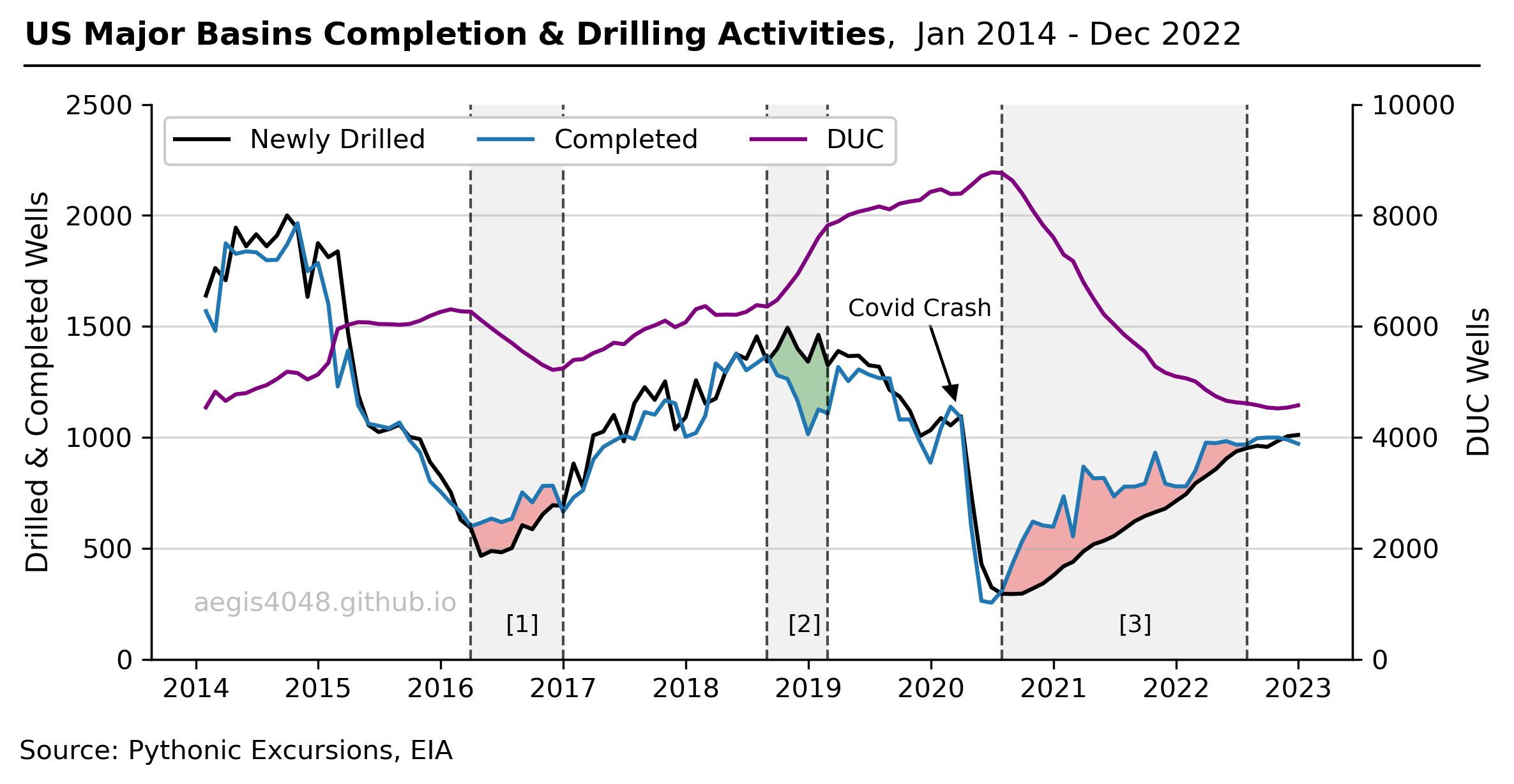
DUC Wells and Their Economic Complications
During the Covid-19 Pandemic, the operators opted not to drill new wells, but instead completed their existing DUC wells to meet demand while conserving cash. This post explains the concept and the economic impact of DUC wells on the US energy industry.
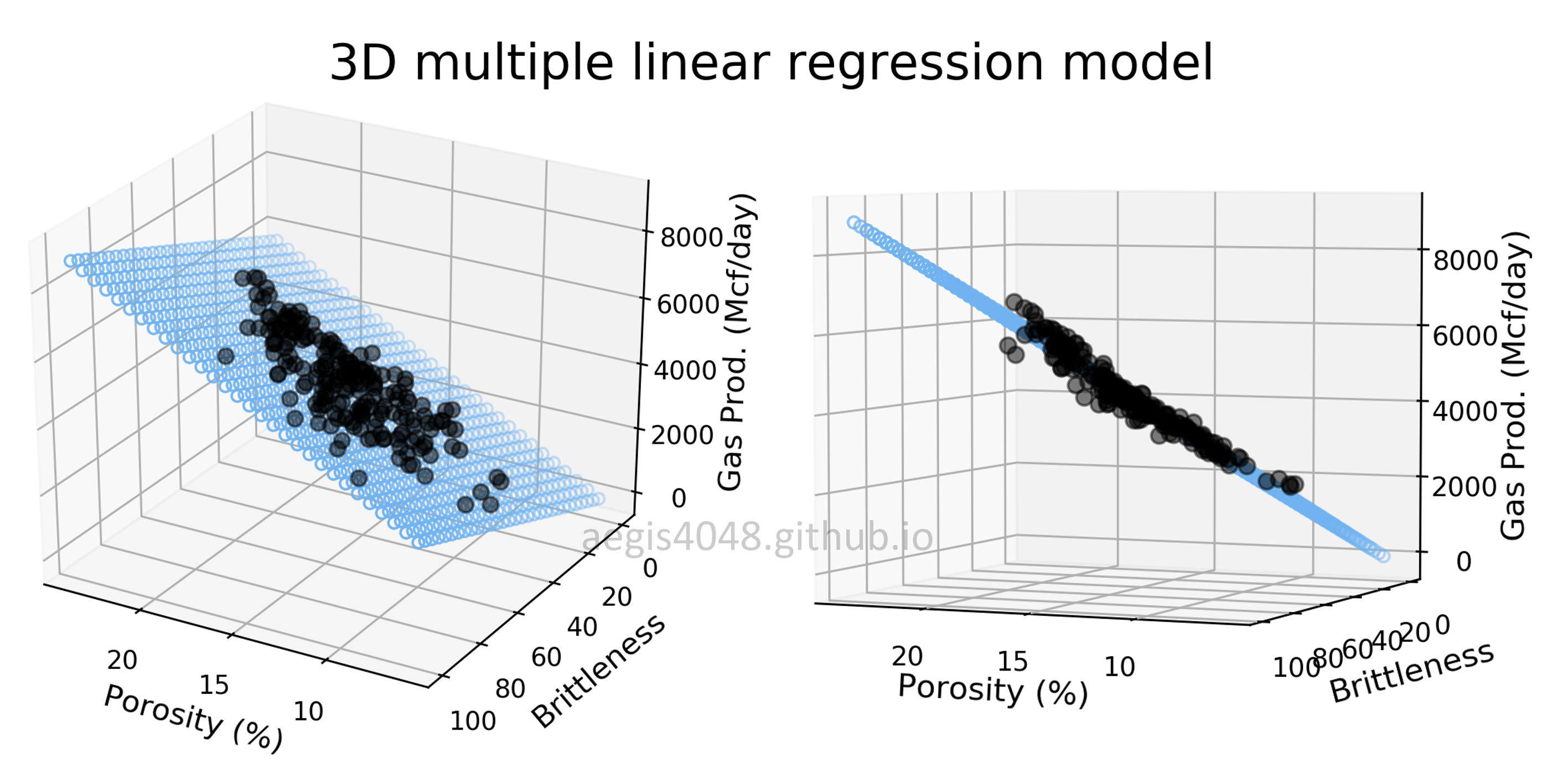
Multiple Linear Regression and Visualization in Python
Data scientists love linear regression for its simplicity. Strengthen your understanding of linear regression in multi-dimensional space through 3D visualization of linear models. This post comes with detailed scikit-learn code snippets for multiple linear regression.
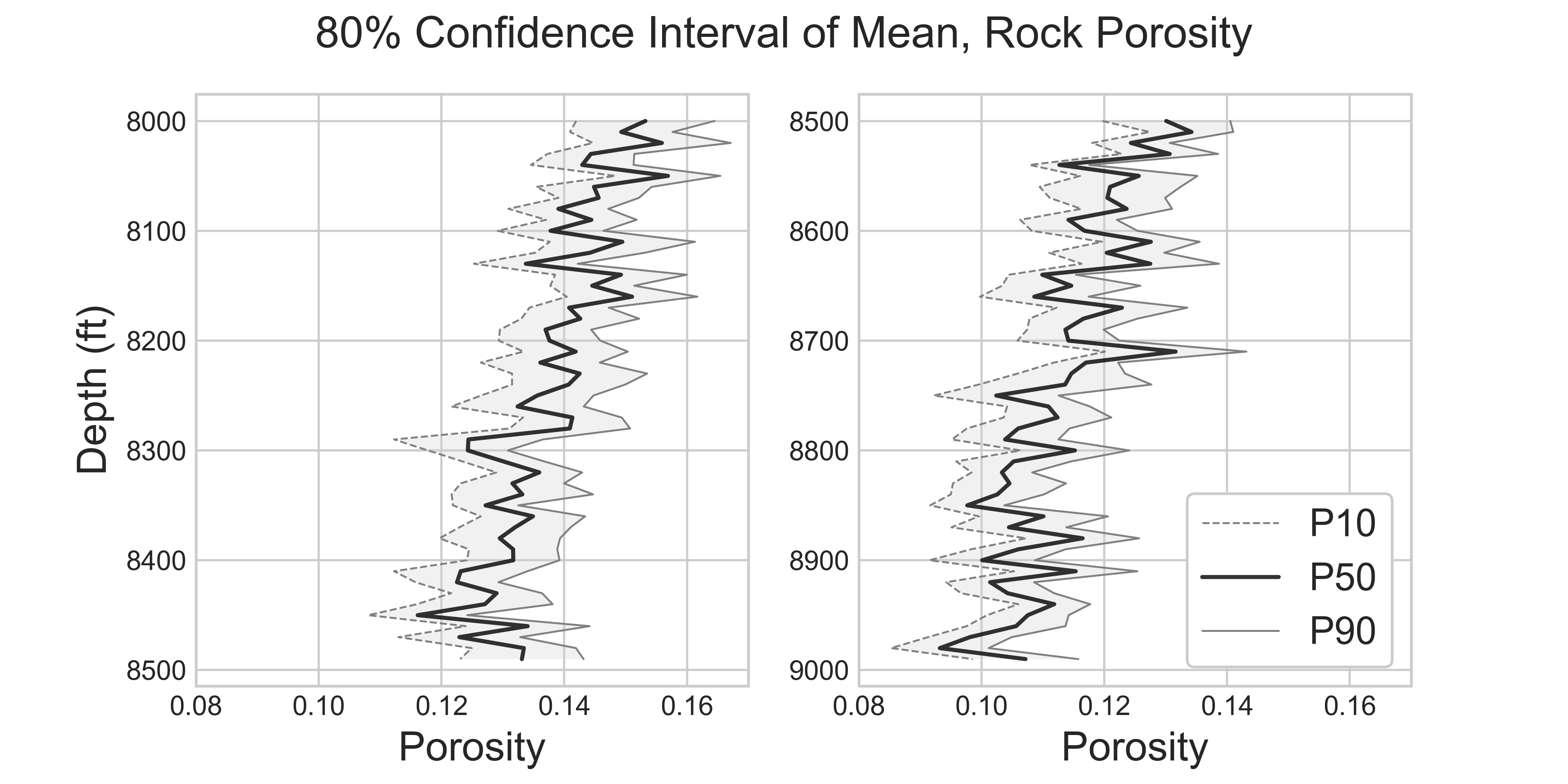
Comprehensive Confidence Intervals for Python Developers
This post covers everything you need to know about confidence intervals: from the introductory conceptual explanations, to the detailed discussions about the variations of different techniques, their assumptions, strength and weekness, when to use, and when not to use.
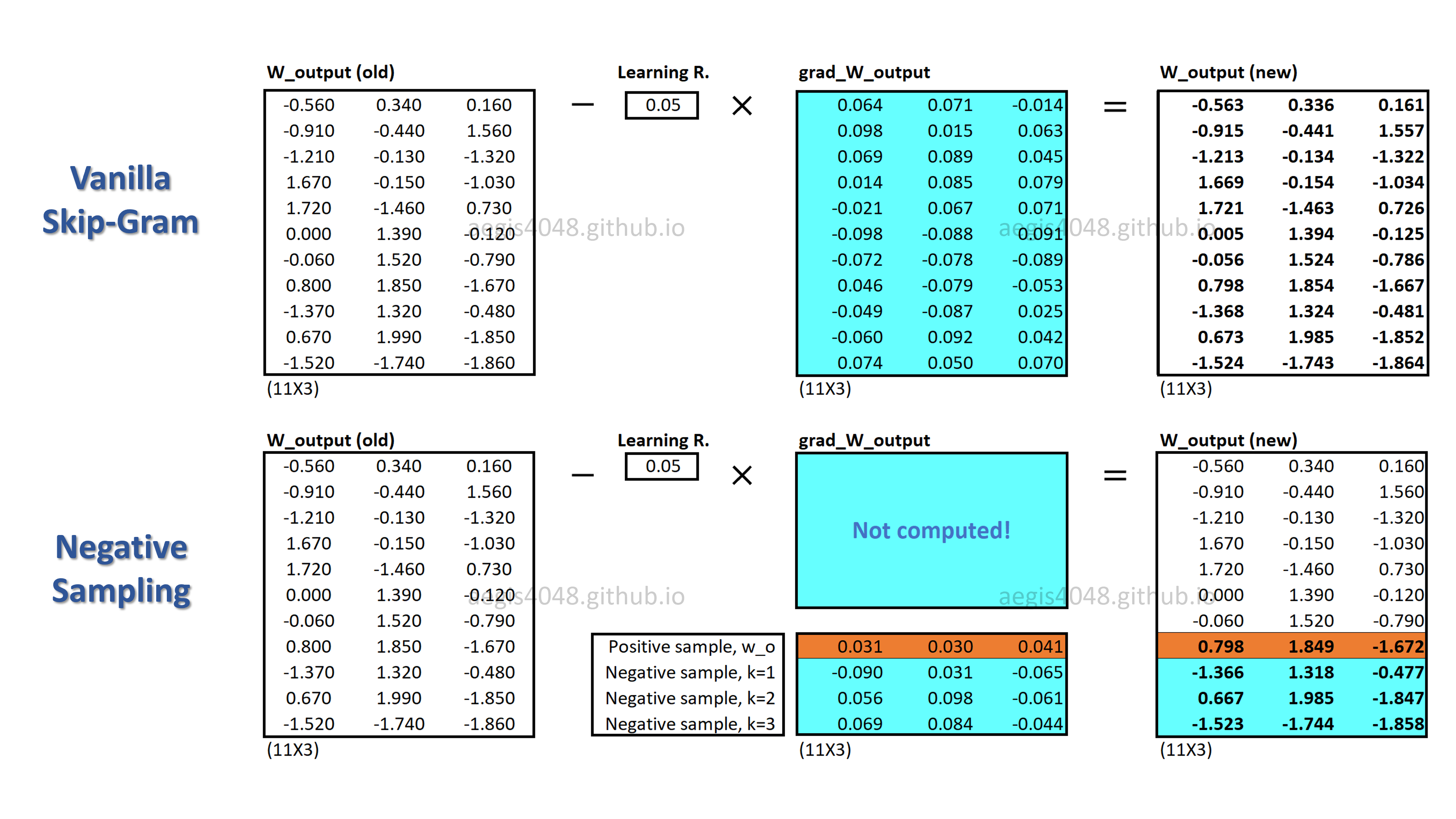
Optimize Computational Efficiency of Skip-Gram with Negative Sampling
When training your NLP model with Skip-Gram, the very large size of vocabs imposes high computational cost on your machine. Since the original Skip-Gram model is unable to handle this high cost, we use an alternative, called Negative Sampling.
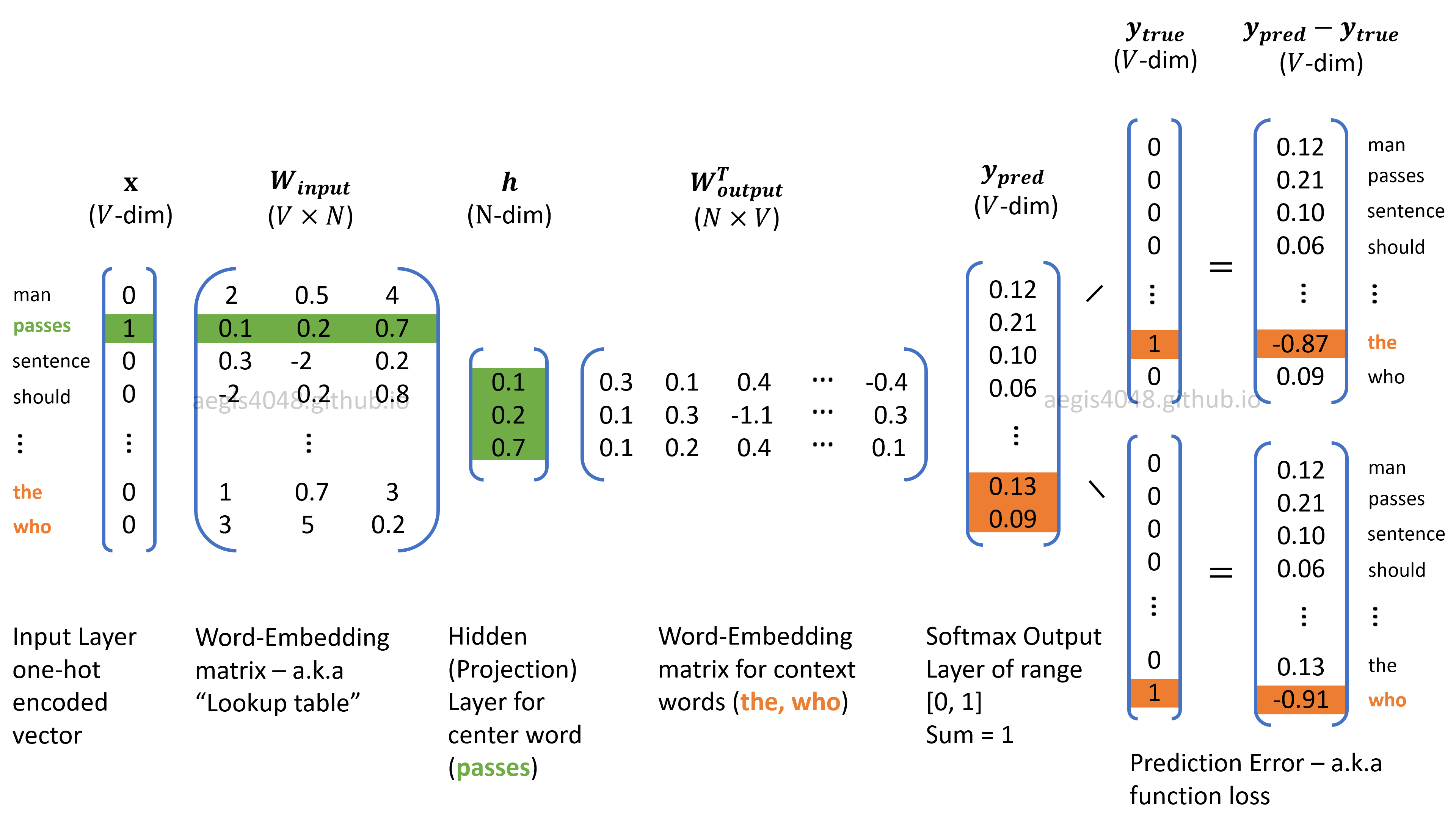
Demystifying Neural Network in Skip-Gram Language Modeling
The past couple of years, neural networks in Word2Vec have nearly taken over the field of NLP, thanks to their state-of-art performance. But how much do you understand about the algorithm behind it? This post will crack the secrets behind neural net in Word2Vec.
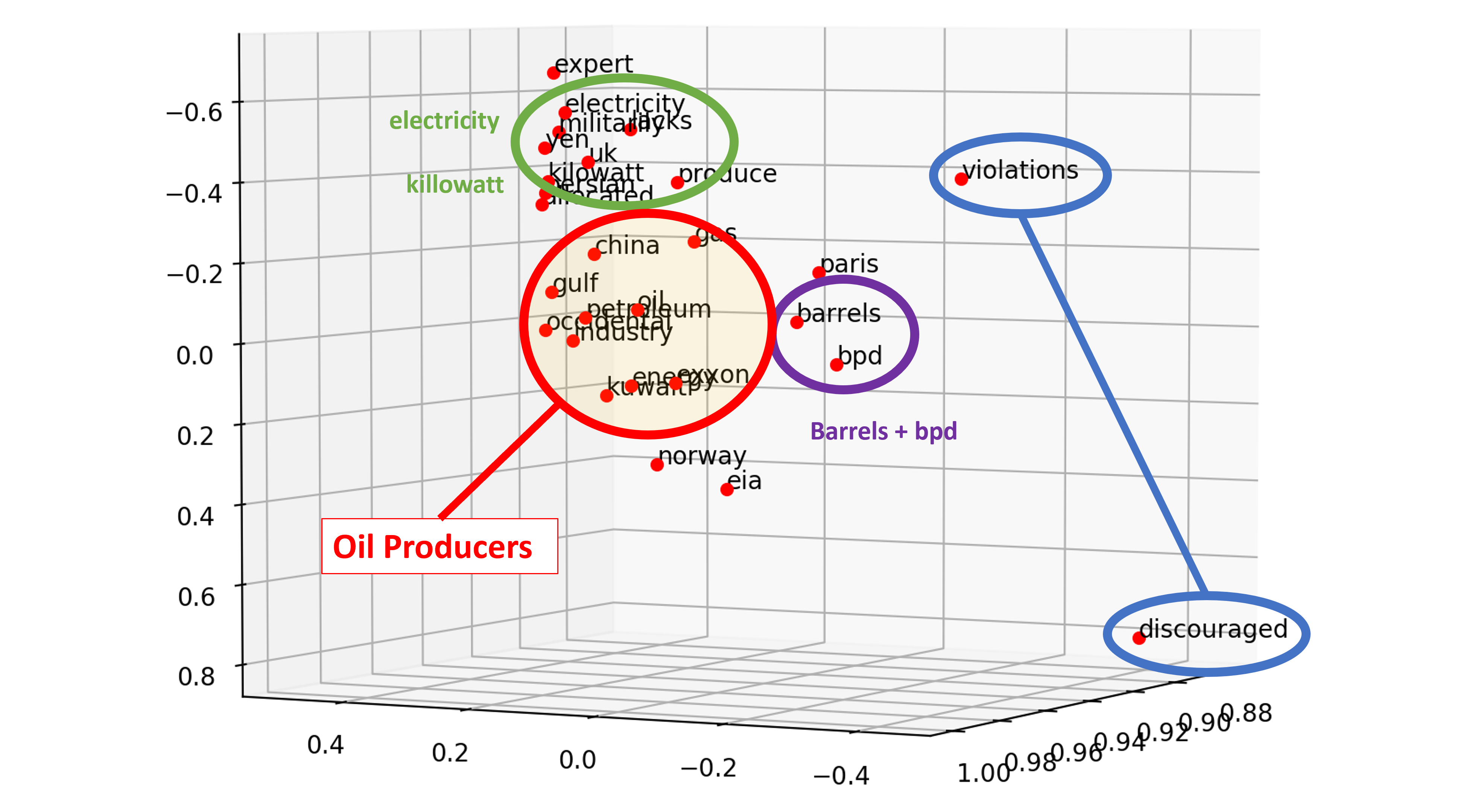
Understanding Multi-Dimensionality in Vector Space Modeling
How does word vectors in Natural Language Processing capture meaningful relationships among words? How can you quantify those relationships? Addressing these questions starts from understanding the multi-dimensional nature of NLP applications.
Transforming Non-Normal Distribution to Normal Distribution
Many statistical & machine learning techniques assume normality of data. What are the options you have if your data is not normally distributed? Transforming non-normal data to normal data using Box-Cox transformation is one of them.
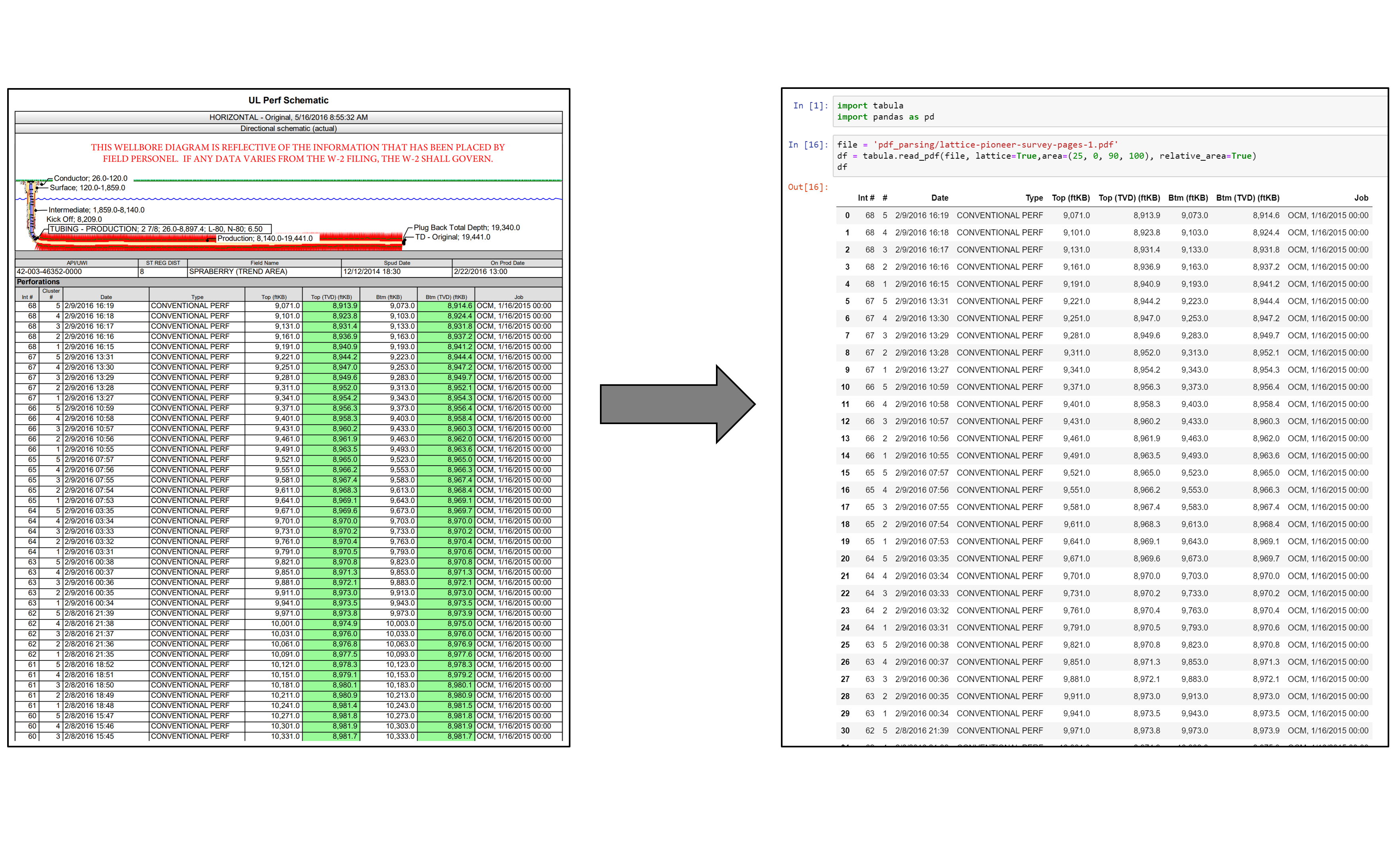
Parse PDF Files While Retaining Structure with Tabula-py
If you ever tried to do anything with data provided to you in PDFs, you know how painful it is — it's hard to copy-and-paste rows of data out of PDF files. Try tabula-py to extract data into a CSV or Excel spreadsheet using a simple, easy-to-use interface.
Creating a Jupyter Notebook-Powered Data Science Blog with Pelican
Are you interested in hosting your own data science blog powered by Jupyter Notebook like this blog? Take a look at Aegis-Jupyter theme I made with Pelican. The set of codes that runs this blog is open-source, available on my Github Repo.
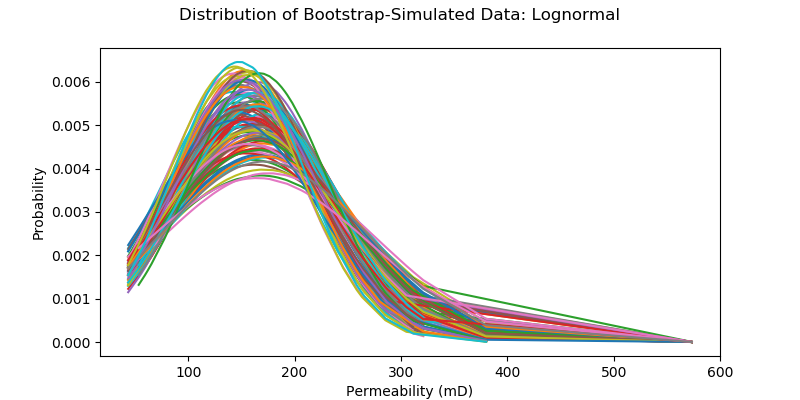
Non-Parametric Confidence Interval with Bootstrap
Bootstrapping is a type of non-parametric re-sampling method used for statistical & machine learning techniques. One application of bootstrapping is that it can compute confidence intervals of any distribution, because it's distribution-free.
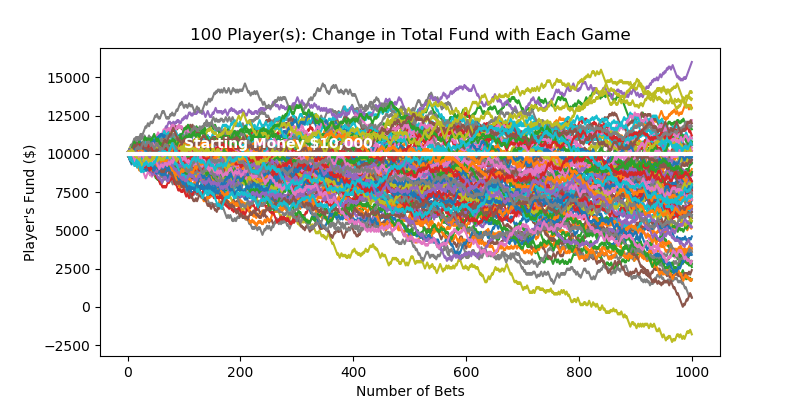
Uncertainty Modeling with Monte-Carlo Simulation
How do casinos earn money? The answer is simple - the longer you play, the bigger the chance of you losing the money. Monte-Carlo simulation can construct its profit forecast model.