Parse PDF Files While Retaining Structure with Tabula-py
Category > Others
Feb 02, 2019If you’ve ever tried to do anything with data provided to you in PDFs, you know how painful it is — it's hard to copy-and-paste rows of data out of PDF files. It's especially hard if you want to retain the formats of the data in PDF file while extracting text. Most of the open source PDF parsers available are good at extracting text. But when it comes to retaining the the file's structure, eh, not really. Try tabula-py to extract data into a CSV or Excel spreadsheet using a simple, easy-to-use interface. One look is worth a thousand words. Take a look at the demo screenshot.
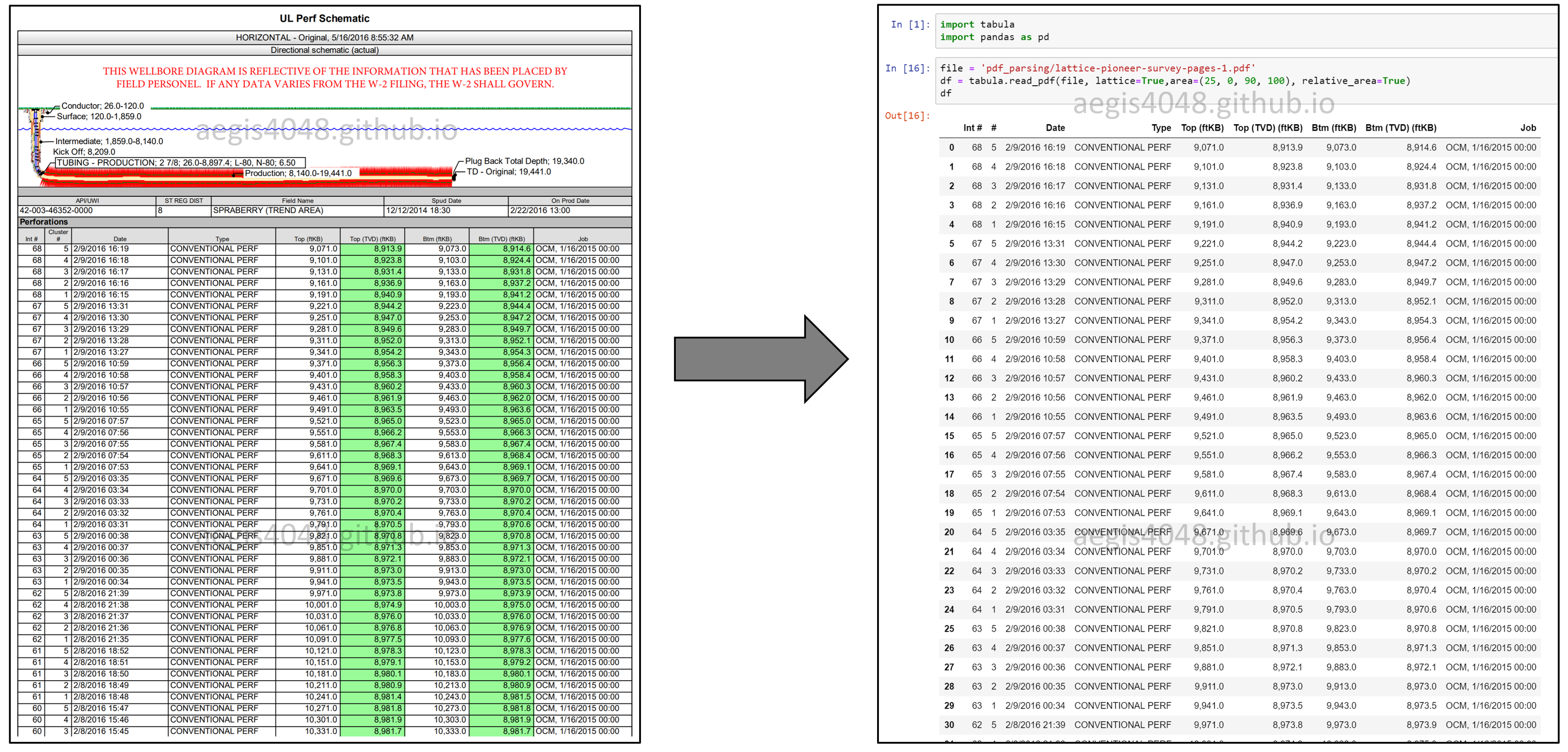
Installations¶
This installation tutorial assumes that you are using Windows. However, according to the offical tabula-py documentation, it was confirmed that tabula-py works on macOS and Ubuntu.
1. Download Java
Tabula-py is a wrapper for tabula-java, which translates Python commands to Java commands. As the name "tabula-java" suggests, it requires Java. You can download Java here.
2. Set environment PATH variable (Windows)
One thing that I don't like about Windows is that it's difficult to use a new program I downloaded in a console environment like Python or CMD window. But oh well, if you are a Windows user, you have to go through this extra step to allow Python to use Java. If you are a macOS or Ubuntu user, you probably don't need this step.
Find where Java is installed, and go to Control Panel > System and Security > System > Advanced system settings > Advanced > Environment Variables... to set environment PATH variable for Java.
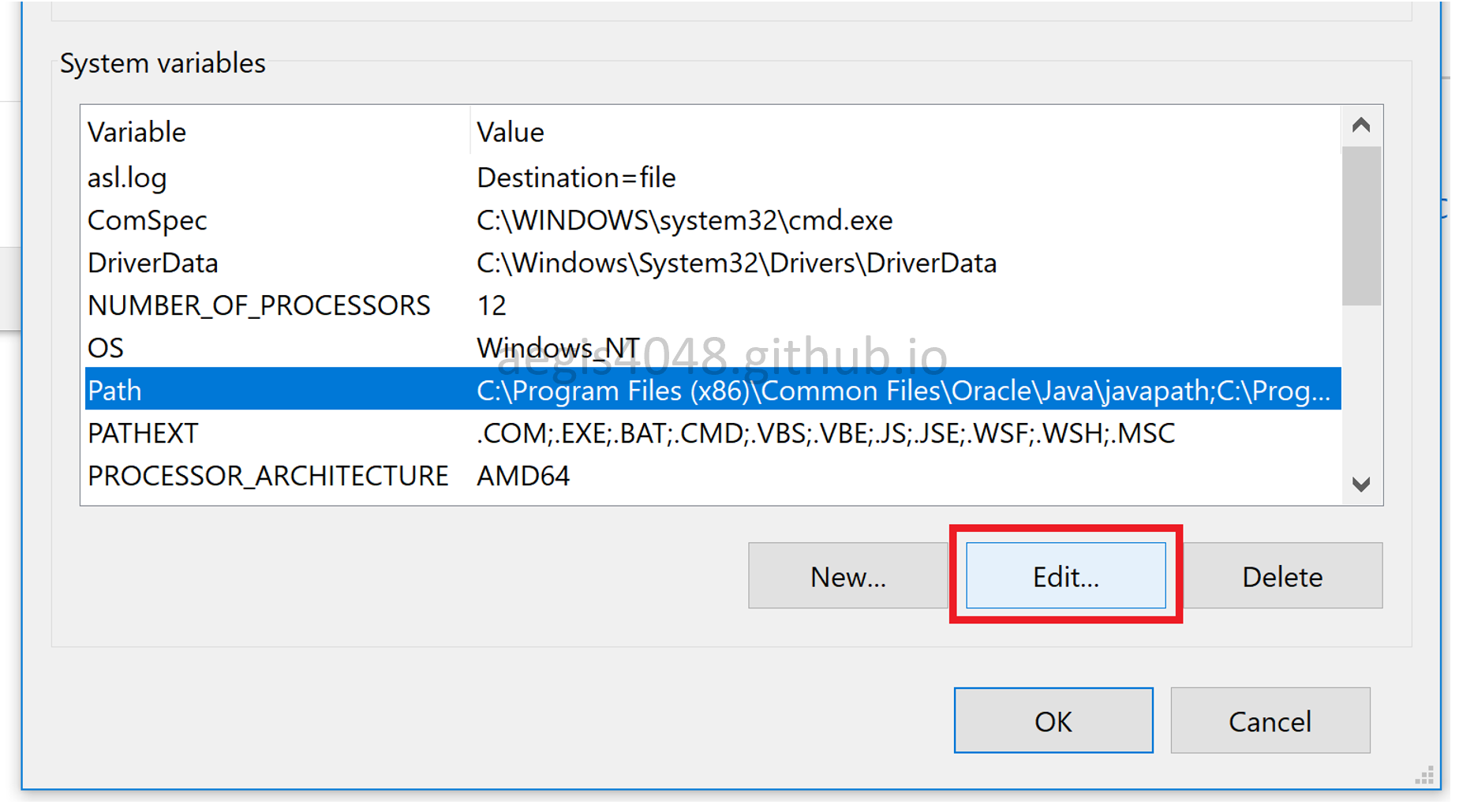
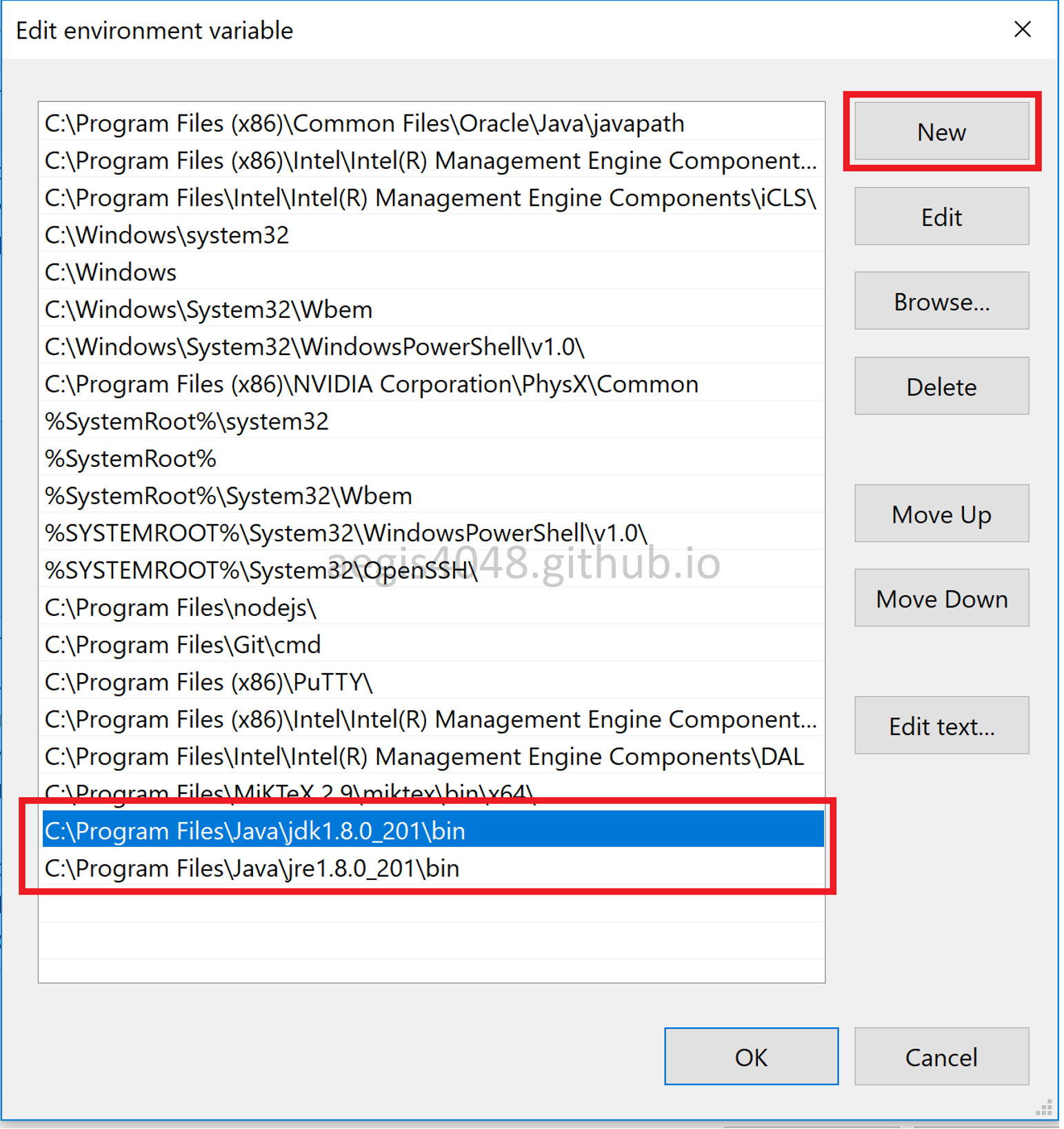
Make sure you have Java\jdk1.8.0_201\bin and Java\jre1.8.0_201\bin in the environment path variable. Then, type java -version on CMD window. If you successfully installed Java and configured the environment variable, you should see something like this:
java -version
java version "1.8.0_201"
Java(TM) SE Runtime Environment (build 1.8.0_201-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.201-b09, mixed mode)
If you don't see something like this, it means that you didn't properly configure environment PATH variable for Java.
3. Re-start Your Command Prompt
Any program invoked from the command prompt will be given the environment variables that was at the time the command prompt was invoked. If you launched your Python console or Jupyter Notebook before you updated your environment PATH variable, you need to re-start again. Otherwise the change in the environment variable will not be reflected.
If you are experiencing FileNotFoundError or 'java' is not recognized as an internal or external command, operable program or batch file inside Jupyter or Python console, it's the issue of environment variable. Either you set it wrong, or your command prompt is not reflecting the change you made in the environment variable.
To check if the change in the environment variable was reflected, run the following code in Jupyter or Python console:
import os
s = os.environ["PATH"].split(';')
for item in s:
print(item)
Something like these must be in the output if everything is working fine:
C:\Program Files\Java\jdk1.8.0_201\bin
C:\Program Files\Java\jre1.8.0_201\bin
4. Install Tabula-py
This is the last step:
pip install tabula-py
Make sure that you install tabula-py, not tabula. Failing to do so will result in AttributeError: module 'tabula' has no attribute 'read_pdf', as discussed in this thread. More detailed instructions are provided in the github repo of tabula-py
Tabula Web Application¶
Tabula supports web application to parse PDF files. You do not need this to use tabula-py, but from my personal experience I strongly recommend you to use this tool because it really helps you debugging issues when using tabula-py. For example, I was tring to parse 100s of PDF files at once, and for some reason tabula-py would return an NoneType object instead of pd.DataFrame object (by default, tabula-py extracts tables in dataframe) for one PDF file. There was nothing wrong with my codes, and yet it would just not parse the file. So I tried opening it on the tabula web-app, and realized that it was actually a scanned PDF file and that tabula is unable to parse scanned PDFs.
Long story short, if it can be parsed with tabula web-app, you can replicate it with tabula-py. If tabula web-app can't, you should probably look for a different tool.
Installations
If you already configured the environment PATH variable for Java, all you need to do is downloading the .zip file here and running tabula.exe. That's it. Tabula has really nice web UI that allows you to parse tables from PDFs by just clicking buttons.
Note
The web-app will automatically open in your browser with 127.0.0.1:8080 local host. If port 8080 is already being used by another process, you will need to shut it down. But normally you don't have to worry about this.
Screenshots
This is what you will see when you launch tabula.exe. Browse... the PDF file you want to parse, and import.
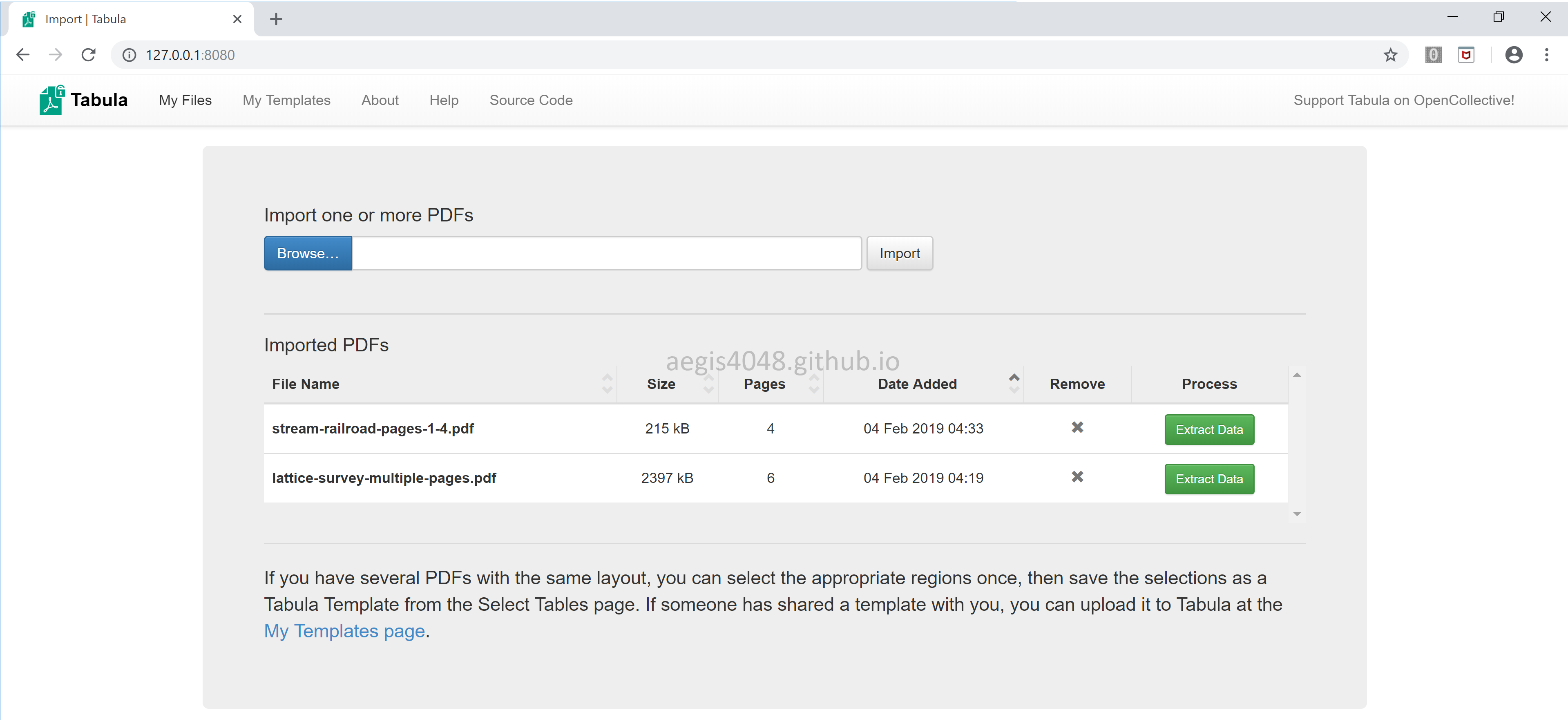
You can either use Autodetect Tables or drag your mouse to choose the area of your interest. If the PDF file has a complicated structure, it is usually better to manually choose the area of your interest. Also, note the option Repeat to All Pages. Selecting this option will apply the area you chose for all pages.
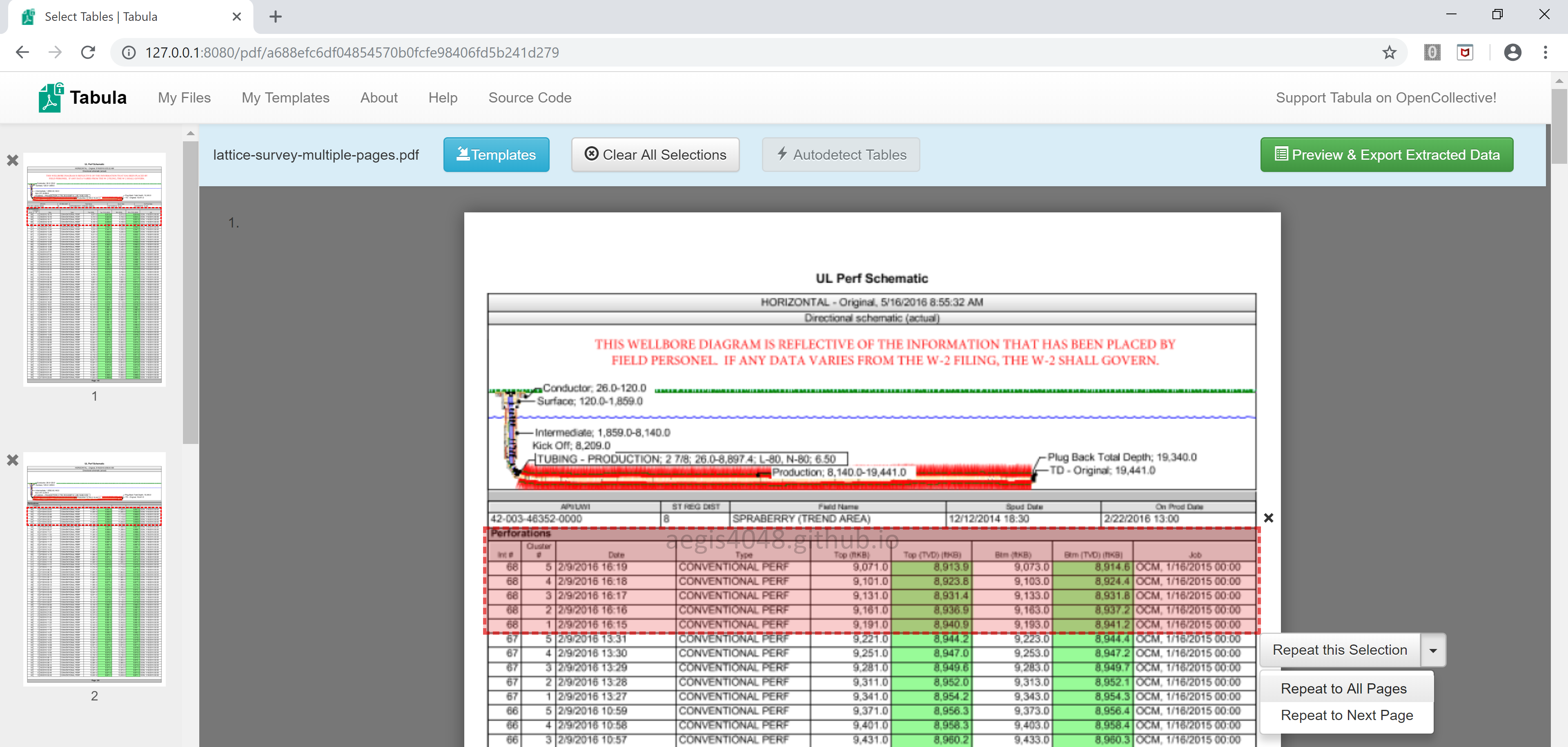
Here's the output. More explanation about Lattice and Stream options will be discussed in detail later.
Template JSON Files
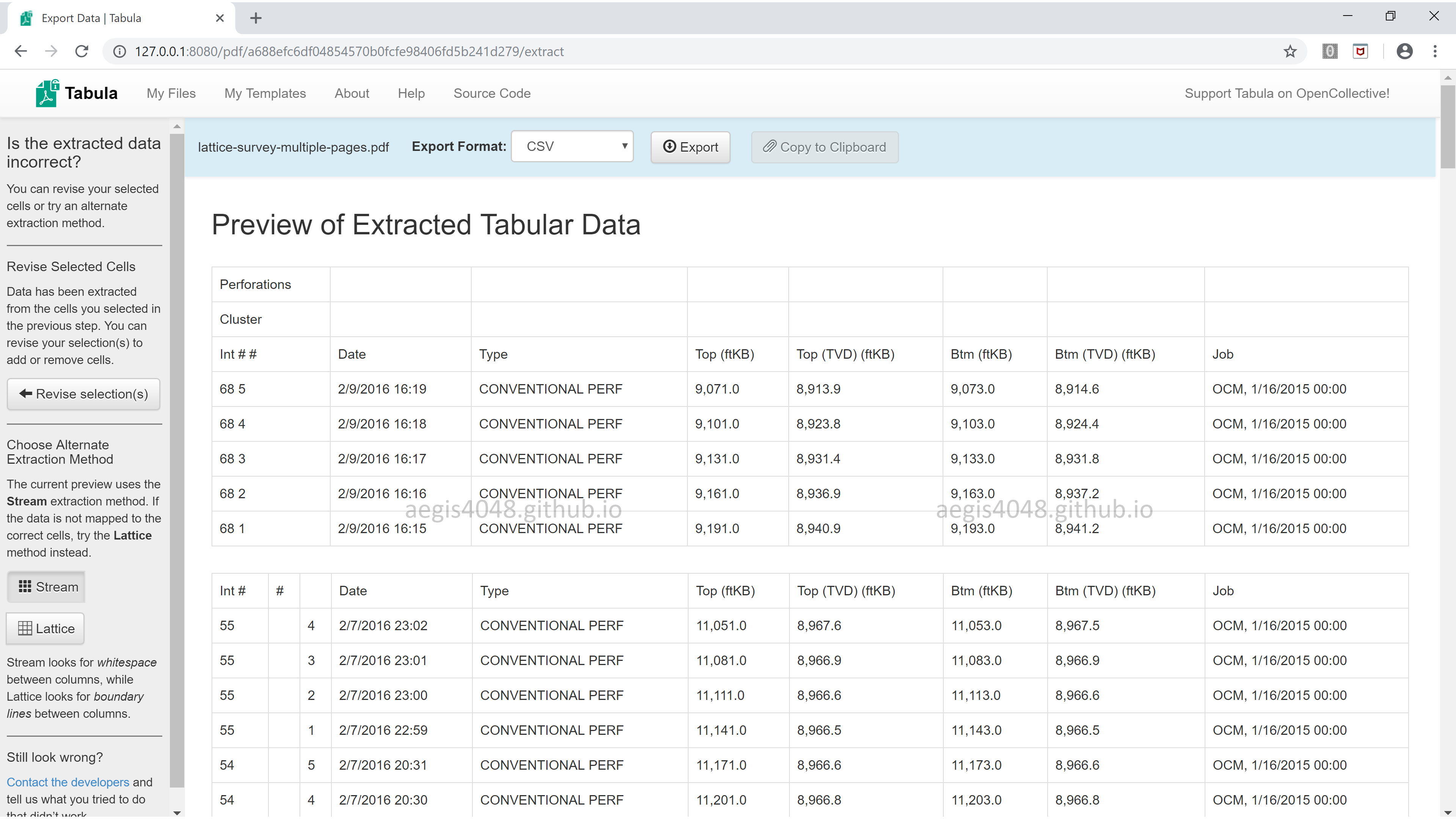
Tabula web-app accepts the user's drag & click as input and translates it into Java arguments that are actually used behind the scenes to parse PDF files. The translated Java arguments are accessible to users in a JSON format.
Select the area you want to parse, and click Save Selections as Template. Then, Download the translated Java arguments in a text JSON file. These arguments are useful when coding arguments for tabula.read_pdf() later.
template.json
{
"page": 2,
"extraction_method": "guess",
"x1": 24.785995330810547,
"x2": 589.3559953308105,
"y1": 390.5325,
"y2": 695.0025,
"width": 564.57,
"height": 304.47
}
Running Tabula-py¶
Tabula-py enables you to extract tables from PDFs into DataFrame and JSON. It can also extract tables from PDFs and save files as CSV, TSV or JSON. Some basic code examples are as follows:
import tabula
# Read pdf into DataFrame
df = tabula.read_pdf("test.pdf", options)
# Read remote pdf into DataFrame
df2 = tabula.read_pdf("https://github.com/tabulapdf/tabula-java/raw/master/src/test/resources/technology/tabula/arabic.pdf")
# convert PDF into CSV
tabula.convert_into("test.pdf", "output.csv", output_format="csv")
# convert all PDFs in a directory
tabula.convert_into_by_batch("input_directory", output_format='csv')
Area Selection
You can select portions of PDFs you want to analyze by setting area (top,left,bottom,right) option in tabula.read_pdf(). This is equivalent to dragging your mouse and setting the area of your interest in tabula web-app as it was mentioned above. Default is the entire page. Also note that you can choose the page, or pages you want to parse with pages option.
The sample PDF file can be downloaded from here.
import tabula
import pandas as pd
file = 'pdf_parsing/lattice-timelog-multiple-pages.pdf'
df = tabula.read_pdf(file, lattice=True, pages=2, area=(406, 24, 695, 589))
df
Alternatively, you can set area with percentage scale by setting relative_area=True. For this specific PDF file, the below area=(50, 5, 92, 100), relative_area=True option is equivalent to area=(406, 24, 695, 589) above.
file = 'pdf_parsing/lattice-timelog-multiple-pages.pdf'
df = tabula.read_pdf(file, lattice=True, pages=2, area=(50, 5, 92, 100), relative_area=True)
df
Notes on Escape Characters
When used as lattice mode, tabula replaces abnormally large spacing between texts and newline within a cell with \r. This can be fixed with a simple regex manipulation.
clean_df = df.replace('\r',' ', regex=True)
clean_df
Lattice Mode vs Stream Mode
Tabula supports two primary modes of table extraction — Lattice mode and Stream mode.
Lattice Mode
lattice=True forces PDFs to be extracted using lattice-mode extraction. It recognizes each cells based on ruling lines, or borders of each cell.
Stream Mode
stream=True forces PDFs to be extracted using stream-mode extraction. This mode is used when there are no ruling lines to differentiate one cell from the other. Instead, it uses spacings among each cells to recognize each cell.
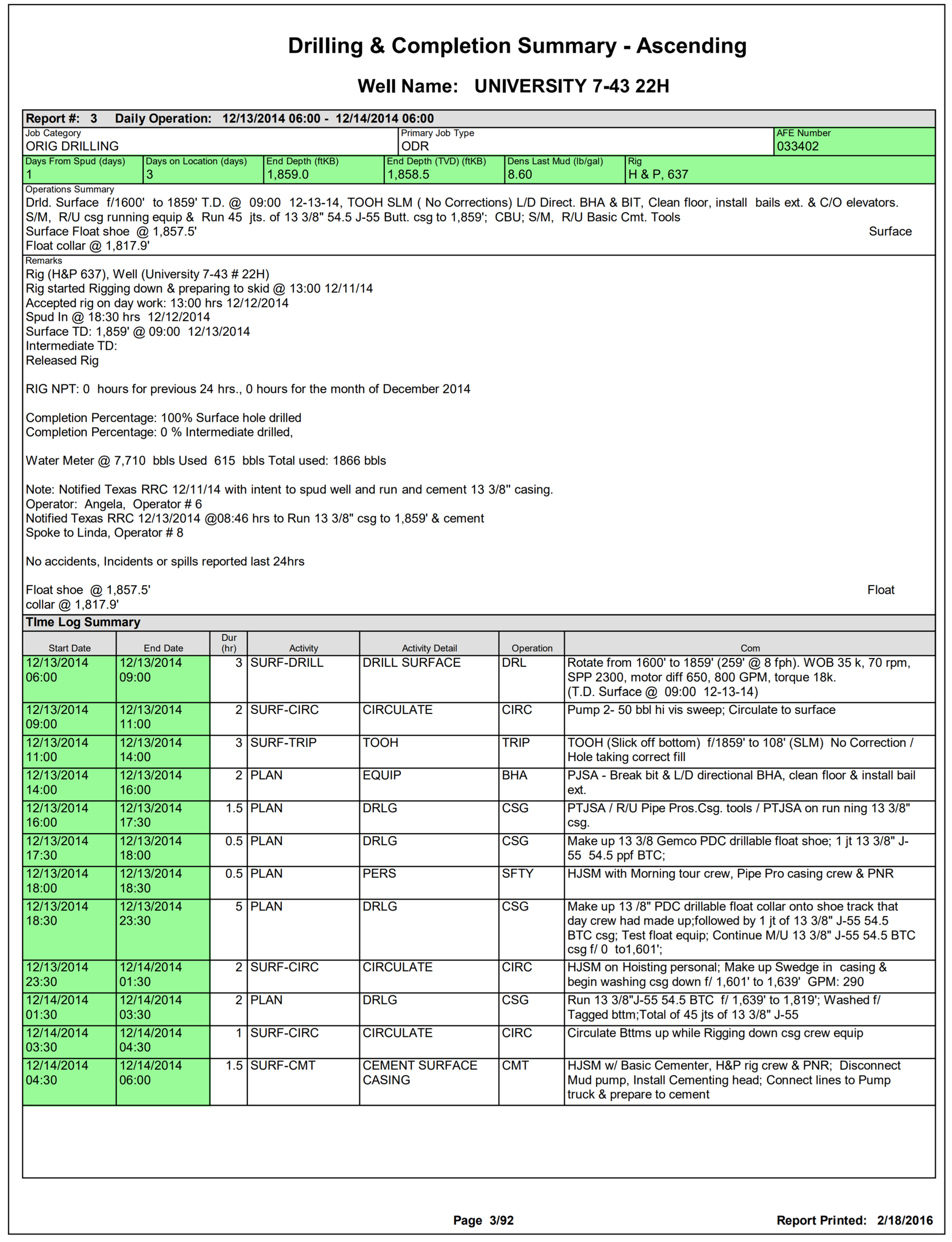
PDF File 1: Lattice mode recommended

PDF file 2: Stream mode recommended
How would it look like if PDF File 1 and PDF file 2 are each extracted in both stream mode and lattice mode?
# PDF File 1: lattice mode
file = 'pdf_parsing/lattice-timelog-multiple-pages.pdf'
df = tabula.read_pdf(file, lattice=True, pages=2, area=(406, 24, 695, 589))
df.head()
# PDF File 1: stream mode
file = 'pdf_parsing/lattice-timelog-multiple-pages.pdf'
df = tabula.read_pdf(file, stream=True, guess=False, pages=2, area=(406, 24, 695, 589))
df.head(11)
# PDF File 2: lattice mode
file = 'pdf_parsing/stream-railroad-pages-1-4.pdf'
df = tabula.read_pdf(file, lattice=True, pages=1, area=(209, 12.5, 387.3, 386))
df
# PDF File 2: stream mode
file = 'pdf_parsing/stream-railroad-pages-1-4.pdf'
df = tabula.read_pdf(file, stream=True, guess=False, pages=1, area=(209, 12.5, 387.3, 386))
df
Observe how lattice mode extraction for PDF file 2 was able to extract only "WELL INFORMATION" string. This is not an error. Recall that lattice mode identifies cells by ruling lines.
Notes About guess option
According to the offical documentation, guess is known to make a conflict between stream option. If you feel something strange with your result, try setting guess=False.
For example, for PDF File 1, if stream mode is used without setting guess=False, it would look like this:
# PDF File 1: stream mode, guess=True
file = 'pdf_parsing/lattice-timelog-multiple-pages.pdf'
df = tabula.read_pdf(file, stream=True, pages=2, area=(406, 24, 695, 589))
df.head(11)
Pandas Option
Pandas arguments can be passed into tabula.read_pdf() as a dictionary object.
file = 'pdf_parsing/lattice-timelog-multiple-pages.pdf'
df = tabula.read_pdf(file, lattice=True, pages=2, area=(406, 24, 695, 589), pandas_options={'header': None})
df.head()
More Documentation¶
Further instructions about tabula-py can be found on its official github repo.
Related Posts
Understanding Multi-Dimensionality in Vector Space Modeling
How does word vectors in Natural Language Processing capture meaningful relationships among words? How can you quantify those relationships? Addressing these questions starts from understanding the multi-dimensional nature of NLP applications.
Demystifying Neural Network in Skip-Gram Language Modeling
The past couple of years, neural networks in Word2Vec have nearly taken over the field of NLP, thanks to their state-of-art performance. But how much do you understand about the algorithm behind it? This post will crack the secrets behind neural net in Word2Vec.
Optimize Computational Efficiency of Skip-Gram with Negative Sampling
When training your NLP model with Skip-Gram, the very large size of vocabs imposes high computational cost on your machine. Since the original Skip-Gram model is unable to handle this high cost, we use an alternative, called Negative Sampling.